네이버 카페 게시글을 크롤링 하려 한다.
python requests를 이용해서 가지고 오려고 했으나
<p class="notice">회원님의 안전한 서비스 이용을 위해 <strong>비밀번호를 확인해 주세요.</strong></p>
<p class="notice02" id="layerd_notice01" style="display:none;">IP가 자주 변경되는 네트워크 환경에서 로그인하는 경우 <br/><strong>IP보안을 해제</strong> 후 이용하시기 바랍니다.</p>
<p class="notice02">다시 한번 <strong>비밀번호 확인</strong> 하시면 이용중인 화면으로 돌아가며, 작성 중이던<br/>내용을 정상적으로 전송 또는 등록하실 수 있습니다.</p>
이렇게 접근할 수 없음을 알 수 있다.
이렇게 되면 selenium을 이용해서 동적으로 접근하기로 한다.
로그인
id 와 password를 입력해서 아래의 코드를 실행하면 로그인이 진행됨을 알 수 있다.
import time
from selenium import webdriver
import csv
import pandas as pd
from bs4 import BeautifulSoup as bs
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from datetime import datetime
import re
url='https://nid.naver.com/nidlogin.login'
id='id'
pw='password'
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"])
# chrome_options.add_argument("headless") # headless option
browser = webdriver.Chrome(options=chrome_options)
browser.get(url)
browser.implicitly_wait(2)
browser.execute_script(f"document.getElementsByName('id')[0].value=\'{id}\'")
browser.execute_script(f"document.getElementsByName('pw')[0].value=\'{pw}\'")
browser.find_element(by=By.XPATH,value='//*[@id="log.login"]').click()
time.sleep(1)
html 접근
baseurl = 'https://cafe.naver.com'
clubid = 'clubid'
menuid = 'menuid'
cafemenuurl = f'{baseurl}/ArticleList.nhn?search.clubid={clubid}&search.menuid={menuid}&search.boardtype=L&userDisplay=50'
크롤링하려는 카페의 clubid와 menuid를 알아야 한다.
clubid는 카페 id, menuid는 카페의 게시판 id
아래의 카페를 예로 들면, (url : https://cafe.naver.com/cafe1535 )
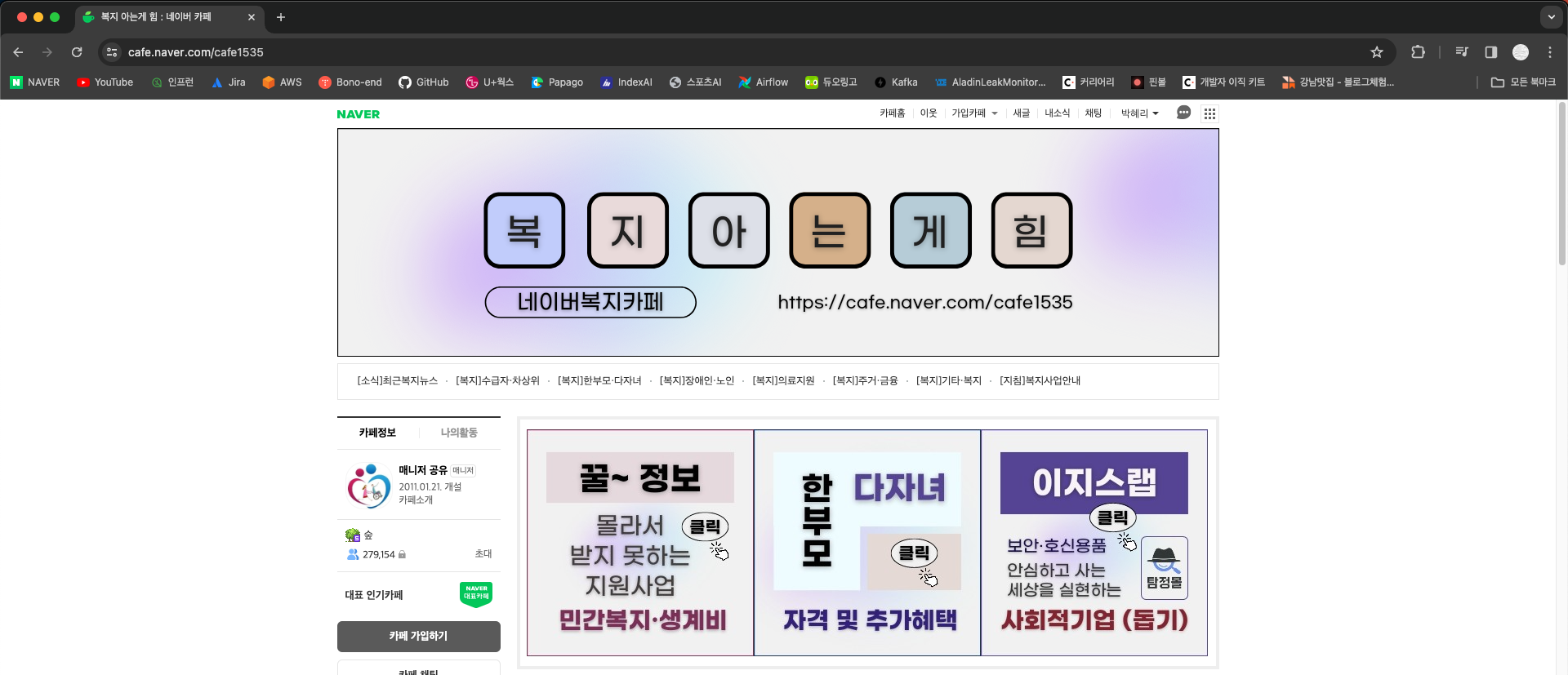
여기에서 원하는 게시판으로 이동하면


url에 변화가 없다
그렇기 때문에 개발자 도구에서 요소 검색으로 알아낸다.

내가 원하는 게시판 a 링크는 /ArticleList.nhn?search.clubid=22243426&search.menuid=54&search.boardtype=L 임을 알 수 있다.
crawling code
i = 0
while(True):
pageNum = i + 1
userDisplay = 50
browser.get(f'{cafemenuurl}&search.page={str(pageNum)}')
browser.switch_to.frame('cafe_main')
soup = bs(browser.page_source, 'html.parser')
soup = soup.find_all(class_ = 'article-board m-tcol-c')[1]
datas = soup.select("#main-area > div:nth-child(4) > table > tbody > tr")
for data in datas:
article_info = data.select(".article")
article_href = article_info[0].attrs['href']
article_href = f'{baseurl}{article_href}'
browser.get(article_href)
browser.switch_to.frame('cafe_main')
article_soup = bs(browser.page_source, 'html.parser')
data = article_soup.find('div', class_='ArticleContentBox')
article_title = data.find("h3", {"class" : "title_text"})
article_date = data.find("span", {"class": "date"})
article_content = data.find("div", {"class": "se-main-container"})
article_author = data.find("button", {"class": "nickname"})
if article_title == None :
article_title = "null"
else:
article_title = article_title.text.strip()
if article_date == None:
article_date="null"
else:
article_date_str = article_date.text.strip()
article_date_obj = datetime.strptime(article_date_str, '%Y.%m.%d. %H:%M')
article_date = article_date_obj.strftime("%Y-%m-%d %H:%M:%S")
if article_content is None:
article_content = "null"
else:
article_content = article_content.text.strip()
article_content = " ".join(re.split("\s+", article_content, flags=re.UNICODE))
if article_author is None:
article_author = "null"
else:
article_author = article_author.text.strip()
f = open(f'test.csv', 'a+', newline='', encoding = "utf-8")
wr = csv.writer(f)
wr.writerow([article_title, article_author, article_date, article_href, article_content])
f.close()
browser.back()
time.sleep(1)
browser.close()
나는 게시글 제목(article_title), 게시글 작성자(article_author), 게시글 시간(article_date), 게시글 링크(article_href), 게시글 내용(article_content) 을 가지고 오고 있다.
추가로 가지고 오고 싶은 요소 들은 html에서 필요한 것들을 쏙쏙 뽑아오면 될 듯
그리고 지금은 while 문으로 계속 끝없이 돌도록 되어 있는데, 조건이 필요할 경우 추가하여 사용하면 될 듯함
output
나는 csv 파일에 데이터 쌓도록 되어 있어서 아래처럼 볼 수 있다.

전체코드
import time
from selenium import webdriver
import csv
import pandas as pd
from bs4 import BeautifulSoup as bs
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from datetime import datetime
import re
url='https://nid.naver.com/nidlogin.login'
id='id'
pw='password'
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"])
# chrome_options.add_argument("headless") # headless option
browser = webdriver.Chrome(options=chrome_options)
browser.get(url)
browser.implicitly_wait(2)
browser.execute_script(f"document.getElementsByName('id')[0].value=\'{id}\'")
browser.execute_script(f"document.getElementsByName('pw')[0].value=\'{pw}\'")
browser.find_element(by=By.XPATH,value='//*[@id="log.login"]').click()
time.sleep(1)
baseurl = 'https://cafe.naver.com'
clubid = 'clubid'
menuid = 'menuid'
cafemenuurl = f'{baseurl}/ArticleList.nhn?search.clubid={clubid}&search.menuid={menuid}&search.boardtype=L&userDisplay=50'
i = 0
while(True):
pageNum = i + 1
userDisplay = 50
browser.get(f'{cafemenuurl}&search.page={str(pageNum)}')
browser.switch_to.frame('cafe_main')
soup = bs(browser.page_source, 'html.parser')
soup = soup.find_all(class_ = 'article-board m-tcol-c')[1]
datas = soup.select("#main-area > div:nth-child(4) > table > tbody > tr")
for data in datas:
article_info = data.select(".article")
article_href = article_info[0].attrs['href']
article_href = f'{baseurl}{article_href}'
browser.get(article_href)
browser.switch_to.frame('cafe_main')
article_soup = bs(browser.page_source, 'html.parser')
data = article_soup.find('div', class_='ArticleContentBox')
article_title = data.find("h3", {"class" : "title_text"})
article_date = data.find("span", {"class": "date"})
article_content = data.find("div", {"class": "se-main-container"})
article_author = data.find("button", {"class": "nickname"})
if article_title == None :
article_title = "null"
else:
article_title = article_title.text.strip()
if article_date == None:
article_date="null"
else:
article_date_str = article_date.text.strip()
article_date_obj = datetime.strptime(article_date_str, '%Y.%m.%d. %H:%M')
article_date = article_date_obj.strftime("%Y-%m-%d %H:%M:%S")
if article_content is None:
article_content = "null"
else:
article_content = article_content.text.strip()
article_content = " ".join(re.split("\s+", article_content, flags=re.UNICODE))
if article_author is None:
article_author = "null"
else:
article_author = article_author.text.strip()
f = open(f'test.csv', 'a+', newline='', encoding = "utf-8")
wr = csv.writer(f)
wr.writerow([article_title, article_author, article_date, article_href, article_content])
f.close()
browser.back()
time.sleep(1)
browser.close()참고
다들 이 게시글 보고 진행한 듯 함
정리가 너무 잘 되어 있음
[Python] 네이버 카페 게시글 크롤러(feat. 크롬 드라이버 & 셀레니움)
네이버 카페 게시글의 제목과 링크를 크롤링 하기 위한 코드이다. 아마 가장 깔끔하게 잘 돌아가는 코드이지 않을까 싶다. 많은 분들께 도움이 되었으면 한다. 기본적으로 크롬의 버전과 크롬
wookidocs.tistory.com
'👩🏻💻 > python' 카테고리의 다른 글
| [python] Fastapi 애플리케이션 exe 파일로 배포하기 (0) | 2024.11.05 |
|---|---|
| [python] socket 동시 연결 (2) | 2024.10.22 |
| [python] fastapi 실시간 스트리밍 이미지 송출 (1) | 2024.10.21 |
| [python] TypeError: 'type' object is not subscriptable (1) | 2024.05.02 |
| [python] Received response with content-encoding: gzip, but failed to decode it. (0) | 2024.02.19 |


